tweetorials
During the summer of 2024, I worked collaboratively with a team of five other computer science undergraduate/graduate researchers at Columbia University’s Computational Design Lab to refine an interactive tool in development that generated X threads. The tool utilizes LLMs to facilitate science communication on social media in the form of X threads that explain a general, scientific topic.
I contributed to the creation of the tool’s task flow and then collaborated with fellow researchers to design and conduct an evaluative study on reader responses to X thread generations.
OUTPUT:Submitted our paper to a human-computer interaction conference!
TEAM: Juna Kawai-Yue, Grace Li (lead researcher), Yuanyang Teng, Unaisah Ahmed, Anatta Tantiwongse, Jessica Liang, Prof. Lydia Chilton (P.I.)
DURATION:June 2024-September 2024
SKILLS:Task flow design, study design, survey design
PROBLEM:Traditional science communication, including academic papers and textbooks, can often be too formal and difficult for general audiences to understand, but social media can make scientific topics more approachable by framing content as relatable and engaging. A popular site often used for explaining scientific concepts is Twitter/X, especially through the form of threads. However, it can be challenging for science experts to tailor their writing for Twitter/X due to problems such as finding appropriate examples to explain concepts or using conversational tones.
OUR SOLUTION: Our project, “Tweetorials”, uses writers’ inputs and guides them through an interactive tool leveraging LLMs to build a Twitter/X thread step by step.
Users should be able to input a topic of interest on the site and follow a series of steps where they can generate various components of the thread, leading to a final, publishable Tweetorial that they can then post on social media or make minor edits to.
WHAT DID WE DO?In order to refine Tweetorials, we went through the following steps:
We conducted a literature review and examined existing scientific communication threads for writing strategies
Established the tool’s task flow by writing our own threads to understand a common workflow
Reformatted the interactive site for the tool and fine-tuned its GPT prompts
Created an evaluation guide for threads generated by our tool and defined research questions for a study on readers’ responses to generated threads
Designed a survey and performed an ablation study on readers
Developed key insights based on our findings

WHAT STRATEGIES DO TWITTER/X THREADS EXPLAINING SCIENTIFIC TOPICS USE?How would we design the tool’s task flow to closely represent how a writer would create scientific explanations in the form of Twitter/X threads?
We firstly conducted literature reviews to understand commonly used writing strategies across popular X threads explaining scientific topics. Our team also examined a previously collected database of threads to see how these strategies were implemented. We noticed writing strategies that were commonly used or specific to X threads.

First six annotated tweets of a thread about dung beetle navigation by @GeneticJen.
BUT HOW WOULD WRITERS CREATE THREADS USING THE STRATEGIES WE FOUND?In order to further understand this question, we decided to attempt the process ourselves. We each wrote 5+ X threads on STEM-related topics we had studied utilizing the writing strategies we found. Our threads went through multiple rounds of iterative feedback each. During this process, I began to follow a consistent workflow in writing my threads.
We translated elements of this workflow as well as workflows created by other team members into restructuring the website’s task flow.
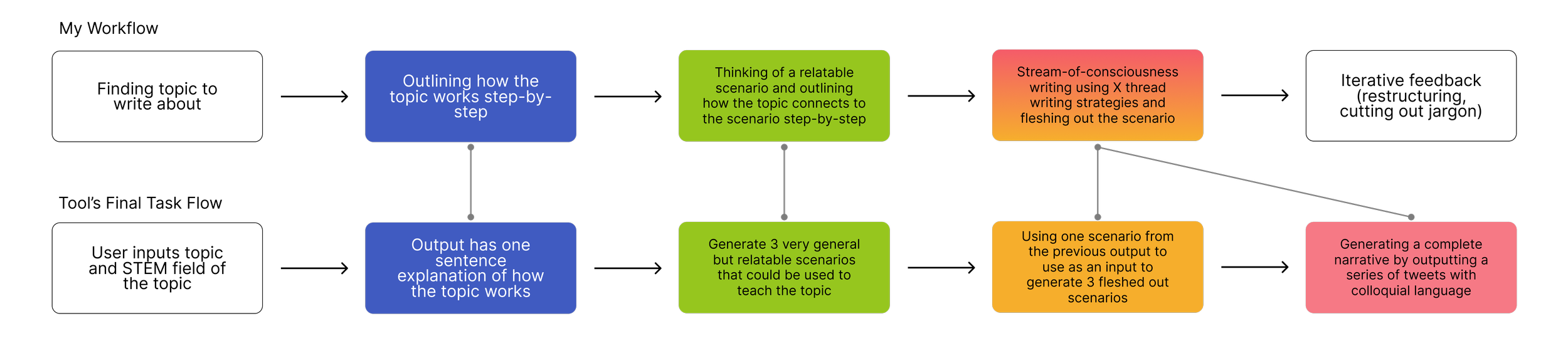
This task flow changed the LLM prompts and how they were used (which we finalized in the prompt engineering process) to generate outputs utilized as a foundation for creating the threads.
HOW WOULD WE EVALUATE OUR GENERATED THREADS?Following our newly established task flow for the tool, members of our team fine-tuned the prompts and coded the tool accordingly. But of course, after we finished refining the tool, we needed to understand how actually “good” our generated threads were and if our new task flows worked.
We knew the best way to evaluate how “good” our threads were was to get readers (an average student scrolling through Twitter/X) to judge them, but how would we define the metrics necessary?
How much would readers prefer generated threads that used the writing strategies we identified on social media–in essence, how crucial is each point in the task flow in generating threads that readers prefer? And how would we measure these?
Figuring out how to measure readers’ responses to the generated threads was tricky because we would have to rely purely on attitudinal metrics. We first decided to create an evaluation matrix of high level concepts based on our established task flow and prompts that would help us score generated threads.
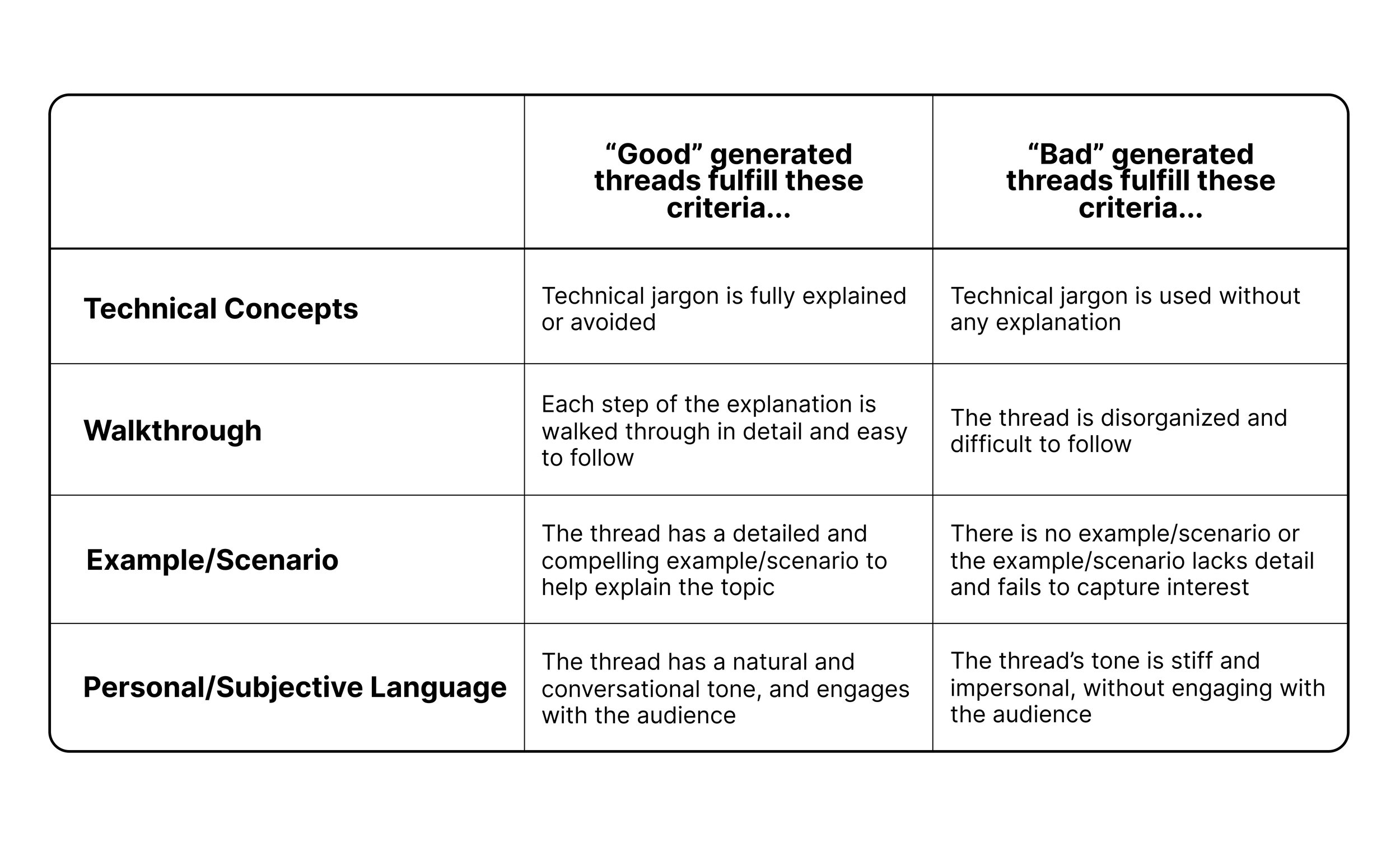
A simplified version of our evaluation matrix.
We used the matrix to define a series of research questions/conditions that would help guide our generated thread evaluations with readers. Each research question/condition corresponds to a step in our task flow.
Research Question 1:
Do people prefer threads with an example/scenario or without one?
Research Question 2:
Do people prefer a step-by-step walkthrough of the topic?
Research Question 3:
Do people prefer narratives with personal and subjective language?
EVALUATION (ABLATION) STUDY WITH READERSAfter having defined our evaluation matrix, we then performed an ablation study using a survey we designed to 1) investigate our research questions and 2) compare reader responses towards outputs generated using our current site vs experimental outputs missing a core part of our task flow. We also conducted follow-up interviews with a fifth of the ablation study participants.
Through this study, we were curious about how the intended audience (high school/university students scrolling on social media) for these X threads would respond to our generations.
Goal
To compare reader responses to threads generated with our current user flow vs experimentally generated threads missing core parts of our user flow.
We recruited 35 undergraduate students and recent graduates through school mailing lists, Slack workspaces, and Discord channels. Due to time constraints, we also recruited participants through snowball sampling.
Participants
We generated a dataset of 75 X threads that participants would read and score using a Qualtrics survey of our design. To avoid bias, we randomized the selection of threads participants would read, and employed a between-subjects design, ensuring that they would never read a thread on the same topic more than once. We designed questions corresponding to our evaluation matrix and employed Likert scales for the questions.
Survey
We interviewed 7 of the survey participants to gain deeper insights into the questions explored in the survey and conducted thematic analyses.
Interviews

An example of one of our study conditions. The Experimental Condition (EWP) contains personal/subjective language, while the Baseline Condition (EW) removes personal/subjective language.
KEY FINDINGSOur survey indicated that participants scored X threads generated with our current task flow 13.8% higher on average in terms of engagement and comprehension than experimentally generated threads missing steps of our task flow.
Interviewees said that relatable scenarios and threads with conversational, colloquial tones helped them understand the scientific topic explained in the threads and stay engaged.
Additionally, most interviewees stated that having an example/scenario helped them understand the importance of a topic. Even more found that examples helped them reflect and understand their own experiences better.
“I don’t really care about computer science algorithms, but I do care about how this applies to my own life." (P2)
However, preferences varied among participants, with some participants finding that generated scenarios and conversational tones could detract from understanding the content. Some participants found conversational tones generated in threads were overly casual and simplistic, stating that threads lacking such language felt much more “straightforward”.
Essentially, we found that steps of the task flow, including generating scenarios and threads with personal language, were important in helping readers understand scientific topics explained in threads and helping them stay engaged. Preferences for these techniques, however, largely varied among interviewees, particularly with personal language.
FUTURE STEPSBased on our insights regarding conversational tone preferences, we continued to add options for site users to be presented both generated threads with and without conversational tones, so they could find the degree of conversational tone they are comfortable with using in the threads they will publish.
Future steps also include conducting robust user studies on the generation tool with experts across different STEM subjects, so we can understand how they interact with the tool and if they would utilize it when writing threads explaining scientific topics.
WHAT I LEARNEDAs one of my first projects related to human-computer interaction/UX research, I learned how to rigorously work in collaboration with a team of fellow researchers and organize/distill deliverables in a way that facilitated efficient teamwork.
I also learned the importance of rapid communication when working under highly ambiguous and changing conditions, as well as balancing research timelines. Evaluative research processes can be intense, and learned after this process about how to better design my own studies and surveys.